
Сэмплирование данных
Трудоемкость некоторых алгоритмов Data Mining экспоненциально возрастает с увеличением объема данных и требует часто неприемлемых временных и вычислительных затрат. Поэтому на практике применяется подход, когда построение модели выполняется на выборке данных, в достаточной мере отражающей свойства всей исследуемой совокупности. Процесс формирования такой выборки — сэмплинг, является важнейшим этапом анализа данных. В Loginom это можно сделать с помощью нескольких методов отбора в компоненте Сэмплинг.
В примере показано, как с помощью сэмплинга в 20 раз увеличить скорость обучения нейросети при сохранении качества модели.
Описание алгоритма
Исходные данные
В подмодели Импорт данных загружен набор данных, в котором содержится информация о визитах пользователей, количество записей более 900 000.
В узле Параметры полей изменены типы данных для полей PageViews, Bounces, NewVisits.
Задача — классифицировать пользователей по группам каналов (ChannelGrouping).
Проанализировать исходные данные можно с помощью преднастроенного Визаулизатора Статистика. Поля Bounces и NewVisits имеют значения true и null. Эти поля имеют логический тип, вероятнее всего в строках с пропущенными значениями должны быть значения false.
Подготовка данных
В узле Калькулятор с помощью функции NVL заменяются пустые значения на false:
NVL(new_visits, false)
NVL(bounces, false)
Далее в сценарии вместо полей new_visits и bounces будут соответственно использоваться new_visits_replace и bounces_replace.
Машинное обучение
На данном этапе выполняется построение моделей нейросети на исходном наборе данных и на наборе данных, полученном после сэмплирования. Сравниваются коэффициенты статистических показателей, с помощью которых интерпретируются результаты обучения.
1) Проводится корреляционный анализ, по результатам которого решается, какие поля использовать для обучения модели.
Настройки узла Корреляционный анализ:
- Набор 1 — все поля, кроме ChannelGrouping
- Набор 2 - поле ChannelGrouping
- Остальные настройки можно оставить по умолчанию
Результаты выполнения:
| SocialEngagementType | ChannelGrouping | null |
| Date | ChannelGrouping | -0,22 |
| PageViews | ChannelGrouping | -0,07 |
| Visits_ID | ChannelGrouping | -0,04 |
| Continent | ChannelGrouping | 0,04 |
| SubContinent | ChannelGrouping | 0,06 |
| Country | ChannelGrouping | -0,04 |
| Visits | ChannelGrouping | null |
| Hits | ChannelGrouping | -0,08 |
| Source | ChannelGrouping | 0,87 |
| Medium | ChannelGrouping | 0,82 |
| Browser | ChannelGrouping | 0,10 |
| OperatingSystem | ChannelGrouping | 0,17 |
| IsMobile | ChannelGrouping | -0,23 |
| New Visits (replace) | ChannelGrouping | 0,08 |
| Bounces (replace) | ChannelGrouping | 0,06 |
Поля SocialEngagementType и Visits имеют значения null, поэтому не будут использоваться для дальнейшего анализа.
2) Произведен сэмплинг данных с помощью узла Сэмплинг.
Установлены следующие настройки для узла:
- для параметра Метод сэмплинга — значение Последовательный
- Размер множества — 20%
- Остальные настройки можно оставить по умолчанию
После сэмплирования осталось около 180 000 записей из первоначальных 900 000.
3) На следующем этапе настроены 2 одинаковых узла Нейросеть (классификация). На вход первого узла подан полный набор данных, а на вход второго — набор данных после сэмплинга.
Установлены следующие настройки для узлов Нейросеть (классификация):
- для поля ChannelGrouping — назначение Выходное
- для остальных полей, кроме SocialEngagementType, Visits, Visits_ID — назначение Входное
- для поля Date установлен способ нормализации — Стандартизация, для остальных — Индикатор
- Обучающее множество — 80%, Тестовое — 20%
- остальные настройки оставлены по умолчанию
Результаты выполнения двух моделей:
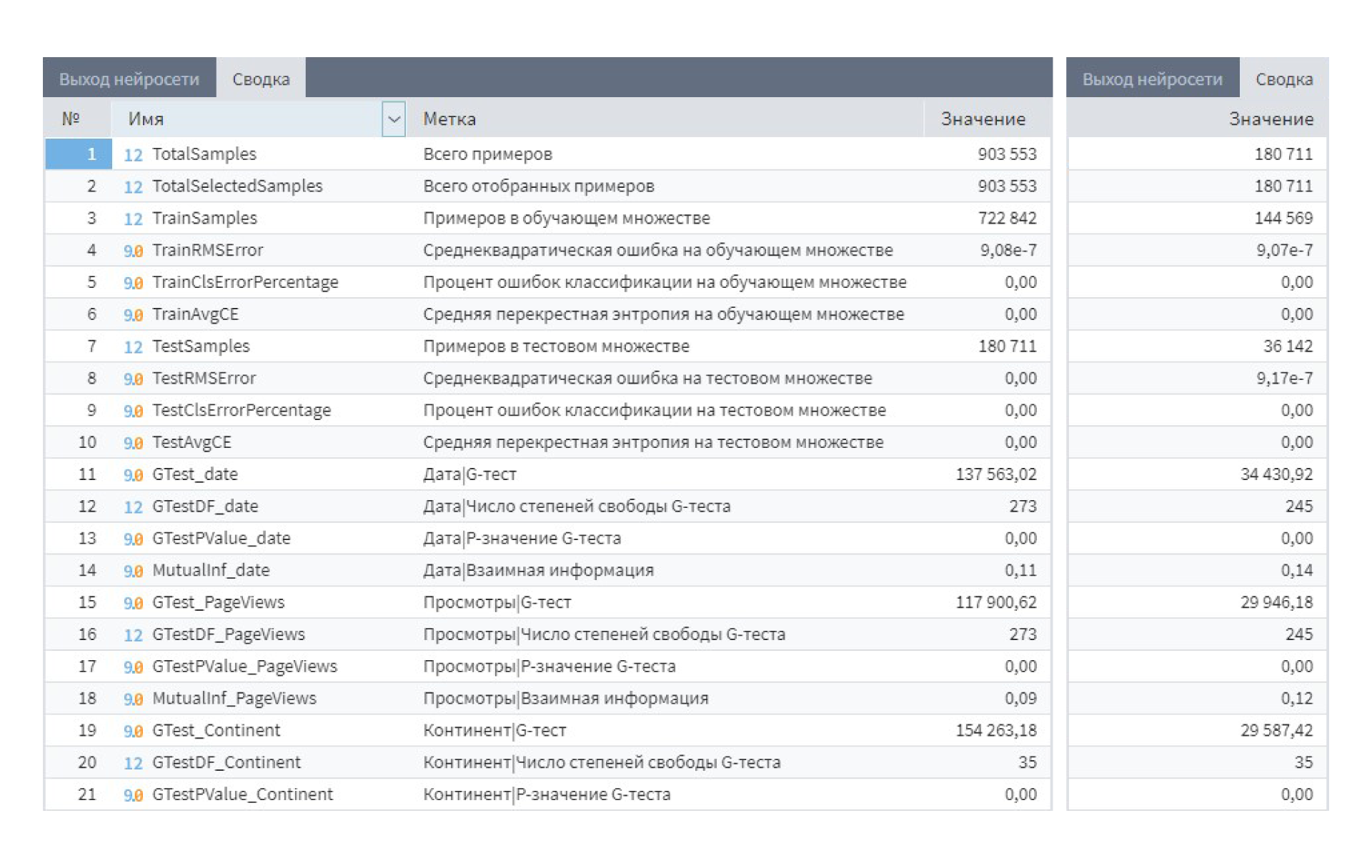
Результаты обучения узлов остались одинаковы. Однако первый узел выполнялся около 3 часов, а второй — около 10 минут. Количество записей в обучающем множестве экспоненциально увеличивает время обучения модели.
Оценка стоимости недвижимости (Нейросеть)
Методы и алгоритмы сэмплинга в анализе данных
Скачайте и откройте файл в Loginom. При необходимости Loginom CE можно скачать бесплатно
Минимальные требования к системе:
- Операционная система: Windows 10 и выше
- CPU x64: 2 core 1
- Оперативная память: 4 GB
- Жесткий диск: 10 GB
1 Поддерживается работа на x64 процессорах Intel Core, AMD FX и более новых, содержащих инструкции SSE4.2, POPCNT.