
Повышение точности кластеризации клиентов с помощью факторного анализа
Факторный анализ — полезный инструмент статистики, упрощающий работу с большими массивами данных. Он позволяет выделить из множества измеряемых характеристик объекта ключевые факторы, которые более компактно описывают его свойства.
Метод уменьшает количество переменных, выбирая самые значимые элементы, облегчая дальнейшее изучение данных и предотвращая ненужную сложность моделей.
В демопримере показано, как компонент Факторный анализ применяется после расчета нормализованного относительного расхода, для уменьшения размерности данных, обнаружения скрытых тенденций и формирования кластеров. Важно помнить, что число факторов выбирается исходя из цели анализа: слишком малое количество снижает глубину понимания, а излишне большое усложняет интерпретацию и делает выводы менее очевидными. Опытным путем для решения данной задачи было выявлено, что оптимальное количество факторов при факторном анализе — от 10 до 15.
Описание алгоритма
1. Задание значений переменных
В порте Переменные пользователя заданы переменные: number_of_factors и number_change. Количество факторов соответствует количеству кластеров. Номер кластера должен входить в диапазон имеющихся кластеров. Переменные используются в узле Факторный анализ и в подмодели Анализ данных в узлах Кластеризация и Калькулятор соответственно.
| Имя | Метка | Значение |
|---|---|---|
number_of_factors |
Количество факторов | 10 |
number_change |
Номер кластера | 8 |
2. Исходные данные
Таблица Исходные данные:
| Имя поля | Метка поля |
|---|---|
| Код | |
| Номер карты | |
| Номер чека | |
| Дата покупки | |
| Группа товара | |
| Количество | |
| Сумма |
3. Нормализованный относительный расход
В подмодели Нормализованный относительный расход с помощью калькулятора рассчитывается показатель Normal Relative Spend. Он представляет собой метрику, предназначенную для оценки распределения расходов покупателя по группам товаров в сравнении с общей структурой выручки магазина.
В подмодели Доля по группе с помощью калькулятора рассчитывается доля покупок клиента в определённой товарной категории относительно общего объёма его покупок по карте.
В подмодели Доля от общего с помощью калькулятора рассчитывается отношение выручки по каждой товарной группе к общему объему продаж магазина.
В узле Слияние полученные данные объединяются в один набор для дальнейших вычислений.
В узле Относительная доля производится расчет отношения между Долей по группе и Долей от общего.
4. Подготовка данных
В подмодели Данные по клиенту формируется новый набор данных. С помощью узла Список групп выделяются все уникальные группы товаров, в узле Список карт группируются все имеющиеся номера карт. Затем полученные наборы объединяются в узле Группы+карты.
С помощью узла Исключение лишних из полученного на предыдущих шагах набора удаляются поля, которые далее не участвуют в обработке. На выходе узла остаются только данные о Группе товара, Номере карты и об Относительной доле.
С помощью узла Слияние к каждому номеру карты добавляется вычисленная ранее Относительная доля. Для слияния используется Левое соединение по полям Группа товара, Номер карты.
В узле Заполнение пропусков заданы следующие настройки:
- Допустимый процент пропусков — 100
- Относительная доля — Метод обработки — Заменять на 0
В узле Кросс-таблица заданы следующие настройки:
- Колонки — Группа товара
- Строки — Номер карты
- Факты — Относительная доля — Метод агрегации — Первый
- Уникальные значения как имена полей — галочка поставлена
5. Факторный анализ
В узле Факторный анализ продолжается подготовка данных к анализу. Проводится процедура уменьшения числа влияющих факторов, направленная на повышение точности дальнейших вычислений.
В узле произведены следующие настройки:
На первой странице мастера настройки для поля Номер карты установлено назначение Не задано, для всех остальных полей — Используемое.
На странице Факторный анализ установлены следующие настройки:
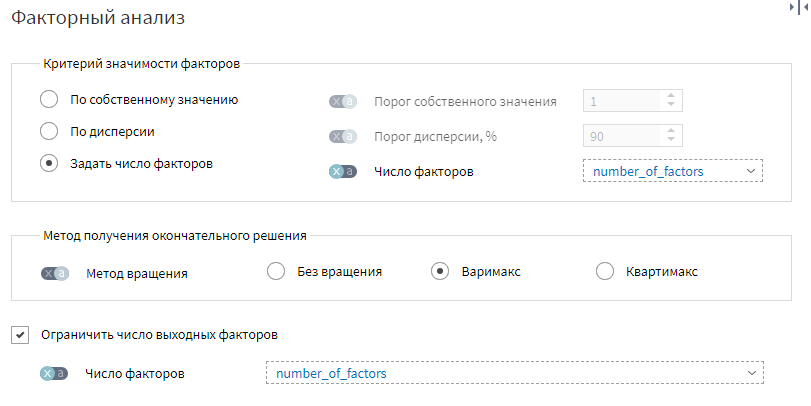
Для выходного порта Факторные нагрузки настроен визуализатор Таблица. Если отсортировать столбец с нужным фактором по убыванию, то первые 2-6 строк с наибольшими значениями будут показывать какие группы товаров составляют данный фактор.
В примере узел настроен и обучен. Если в настройки модели вносятся изменения, то узел нужно переобучить.
6. Анализ данных
Установлены следующие настройки для узла Кластеризация:
- Настройка входных портов — для полей факторов с 1 по 10 — назначение Используемое
- Автоопределение числа кластеров — галочка поставлена
- Максимальное число кластеров — задается управляющей переменной
number_of_factors - Random seed — 1812528348
В случае изменения настроек требуется переобучить модель.
На узел Кластеризация настроен визуализатор Профили кластеров.
На панели инструментов выбраны следующие настройки:
- Индикатор — Гистограмма
- Масштабирование гистограмм — Плотность вероятности
Визуализатор показывает, какие факторы внесли значительный вклад в образование сегмента. Если график на пересечении кластера и фактора существенно отличается от Итого, то это означает что фактор входит в данный сегмент.
Например, для Кластера 8 наиболее значимыми являются факторы 1 и 9.
В узле Калькулятор задается номер кластера, который будет использоваться в последующих узлах.
На узел Калькулятор подается управляющая переменная number_change, при ее редактировании будет изменен номер фактора, который будет рассматриваться в следующем узле.
С помощью узла Исключение лишних из полученного на предыдущих шагах набора удаляются поля, которые далее не участвуют в обработке. На выходе узла остаются только данные о Группах товаров.
Для дальнейшей интерпретации результатов используется компонент Конечные классы. Для него установлены следующие настройки:
- для поля Номер фактора установлено назначение Выходное
- для поля Номер кластера установлено назначение Не задано
- для оставшихся полей установлено значение Входное
- Настройка режима активации узла — Всегда переобучать
В визуализаторе Конечные классы в области начальных классов отображаются поля Столбец с группами товаров и IV (Информационный индекс).
Столбец IV требуется отсортировать по убыванию. На основе IV определяется значимость признака. Чем выше индекс, тем сильнее связь групп товаров с рассчитанным кластером. Первые 3-5 строк с наибольшими значениями IV входят в выбранный ранее кластер. Если одни и те же группы товаров имеют высокое значение в нескольких кластерах, то группы товаров могут быть перемещены в тот кластер, где IV имеет наибольшее значение.
Полученные данные могут быть использованы при составлении картины поведения покупателя или во время последующего анализа.
Для построения устойчивых моделей желательно иметь большее количество наблюдений (строк) относительно числа факторов. Однако на практике часто встречается ситуация, когда количество факторов превышает сотню, тогда как объем выборки ограничен. Применение факторного анализа помогает преодолеть данную проблему, обеспечивая сокращение количества факторов и построение надежной статистической модели.
Скачайте и откройте файл в программе Loginom, которую при необходимости можно скачать бесплатно
Минимальные требования к системе:
- Операционная система: Windows 10 и выше
- CPU x64: 2 core 1
- Оперативная память: 4 GB
- Жесткий диск: 10 GB
1 Поддерживается работа на x64 процессорах Intel Core, AMD FX и более новых, содержащих инструкции SSE4.2, POPCNT.