
Кластеризация транзакций
В основе кластеризации транзакций лежит алгоритм CLOPE, применение которого позволяет обрабатывать огромные массивы транзакционных данных: чеки в супермаркетах, логи посещений веб-ресурсов и другие. Задача состоит в получении такого разбиения всего множества транзакций, чтобы похожие транзакции оказались в одном кластере, а отличающиеся друг от друга — в разных кластерах.
В данном демопримере рассматривается задача по определению кластеров, описывающих съедобные и ядовитые грибы.
Описание алгоритма
1. Импорт данных
Исходный набор данных включает в себя 8124 записи с описанием 22 характеристик грибов. 4208 грибов являются съедобными, 3916 — несъедобными. Количество уникальных характеристик — 116.
| Имя | Метка |
|---|---|
| Класс | |
| Форма шапки | |
| Поверхность шляпки | |
| Цвет шляпки | |
| Синие пятна | |
| Запах | |
| Форма крепления гименофора к ножке | |
| Частота гименофора | |
| Размер гименофора | |
| Цвет гименофора | |
| Форма ножки | |
| Корень ножки | |
| Поверхность ножки выше кольца | |
| Поверхность ножки ниже кольца | |
| Цвет ножки выше кольца | |
| Цвет ножки ниже кольца | |
| Тип покрывала | |
| Цвет покрывала | |
| Количество колец | |
| Остатки частного покрывала | |
| Цвет спор | |
| Частота грибницы | |
| Место обитания |
2. Подготовка данных
Исходный набор данных не пригоден для использования в узле Кластеризация транзакций — его нужно привести к транзакционному виду (Транзакция — Элемент). Узлы, с помощью которых производится трансформация, объединены в подмодель Подготовка данных.
С помощью узла Добавление ID добавлено новое поле — ID, которое необходимо для того, чтобы каждая запись набора имела уникальный идентификатор. Идентификаторы начинаются с 1:
RowNum() + 1
Установлены следующие настройки для узла Свертка столбцов:
- в группу Информационные добавлено поле
ID - в группу Транспонируемые — все остальные поля
| 1 | Класс | ядовитый |
| ... | ... | ... |
| 1 | Цвет гименофора | черный |
В узле Формирование свойства сформировано новое поле property(Свойство) из названия характеристик и их значений с помощью функции Concat:
Concat(display_names, " — ", values)
Итоговый набор данных:
| Класс - ядовитый | Класс | ядовитый | 1 |
| ... | ... | ... | ... |
| Цвет гименофора - черный | Цвет гименофора | черный | 1 |
3. Кластеризация транзакций
На странице Мастера настройки входных полей установлены следующие назначения:
| Имя | Метка | Вид данных | Назначение |
|---|---|---|---|
| ID | Дискретный | Транзакция | |
| Свойство | Дискретный | Элемент | |
| Метки | Дискретный | Не задано | |
| Значения | Дискретный | Не задано |
{kind=link}
Остальные настройки оставлены по умолчанию.
При изменении настроек переобучите модель.
Интерпретация результатов
Для представления результатов используются визуализаторы Таблица и Куб:
Для визуализатора Таблица используется набор данных из порта Параметры кластеров узла Кластеризация транзакций.
Таблица отражает информацию о параметрах разбиения и позволяет оценить кластеры по различным характеристикам:
- Количество транзакций (N)
- Ширина кластера (W)
- Мощность кластера (S)
Можно сортировать кластеры по данным показателям. Например, можно выбрать самые мощные кластеры:
| 17 | 1728 | 35 | 39744 |
| 6 | 1296 | 35 | 29808 |
| 9 | 1296 | 35 | 29808 |
| 2 | 768 | 34 | 17664 |
| 1 | 512 | 33 | 11776 |
С помощью узла Слияние сопоставлены полученные кластеры и характеристики грибов.
Настройки узла:
- Тип операции — Левое соединение
- установлена связь по полю
ID
Критерием качества работы алгоритма служит количество «грязных» кластеров, т.е. таких, в которых присутствуют как съедобные, так и несъедобные грибы. Чем меньше таких кластеров, тем лучше.
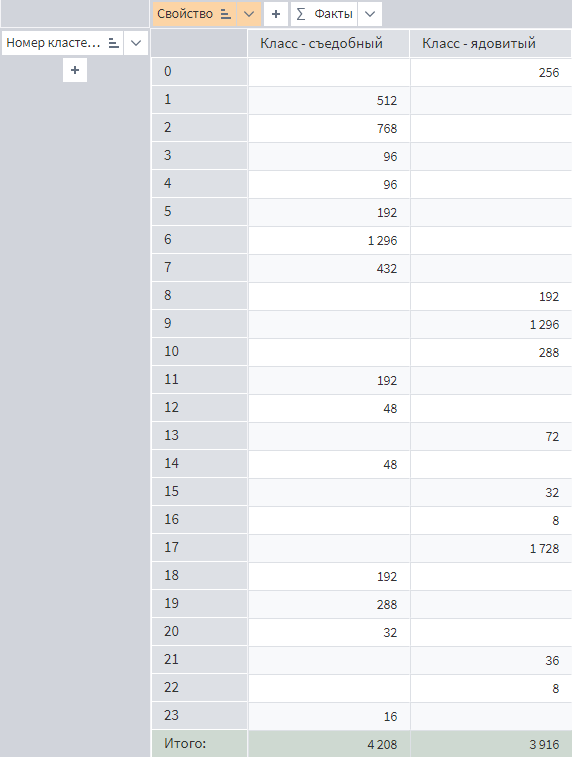
Настроим Куб следующим образом:
- в область Измерений добавлено поле
Номер кластера - в область Факты добавлено поле
Свойство - настроен фильтр для поля
Свойство— отображать только значенияКласс — съедобныйиКласс — ядовитый
Из Куба видно, что в результате кластеризации не получилось ни одного «грязного» кластера, что говорит о качественном разбиении.
Скачайте и откройте файл в Loginom. При необходимости Loginom CE можно скачать бесплатно
Минимальные требования к системе:
- Операционная система: Windows 10 и выше
- CPU x64: 2 core 1
- Оперативная память: 4 GB
- Жесткий диск: 10 GB
1 Поддерживается работа на x64 процессорах Intel Core, AMD FX и более новых, содержащих инструкции SSE4.2, POPCNT.