
Кластеризация
Задача кластеризации является фундаментальной в анализе данных и Data Mining. Кластеризация — объединение объектов или наблюдений в непересекающиеся группы, называемые кластерами.
В Data Mining кластеризация используется для сегментации клиентов и рынков, медицинской диагностики, социальных и демографических исследований, определения кредитоспособности заемщиков и во многих других областях.
Для иллюстрации задачи используется набор данных «Ирисы Фишера». На этом наборе Р. Фишер продемонстрировал работу разработанного им метода дискриминантного анализа.
Описание алгоритма
1. Импорт данных
Набор состоит из данных о 150 экземплярах ирисов. Для каждого из них измерялись четыре характеристики (в сантиметрах).
| Имя | Метка |
|---|---|
| Длина чашелистика | |
| Ширина чашелистика | |
| Длина лепестка | |
| Ширина лепестка |
2.1 EM Кластеризация
В основе EM кластеризации лежит предположение, что любое наблюдение принадлежит ко всем кластерам, но с разной вероятностью. Объект должен быть отнесен к тому кластеру, для которого данная вероятность выше.
Установлены следующие настройки для узла EM Кластеризация:
- для полей
sepal_length,sepal_width,petal_length,petal_width— назначение Используемое - в параметре Заданное число кластеров значение равное — 3
- остальные настройки по умолчанию
В случае изменения настроек переобучите модель.
Интерпретация результатов
В выходном наборе появляются две новые колонки, которые добавились к исходному набору:
- Номер кластера
- Вероятность принадлежности
| 1 | 1.00 | 5.10 | 3.50 | 1.40 | 0.20 | Iris-setosa |
| ... | ... | ... | ... | ... | ... | ... |
| 2 | 1.00 | 7.0 | 3.20 | 4.70 | 1.40 | Iris-versicolor |
| ... | ... | ... | ... | ... | ... | ... |
| 0 | 1.00 | 5.90 | 3.0 | 5.10 | 1.80 | Iris-virginica |
Интерпретацию результатов EM Кластеризации можно посмотреть в визуализаторе Профили кластеров:

В визуализаторе Профили кластеров возможно посмотреть статистические показатели, по которым можно сравнить кластеры между собой:
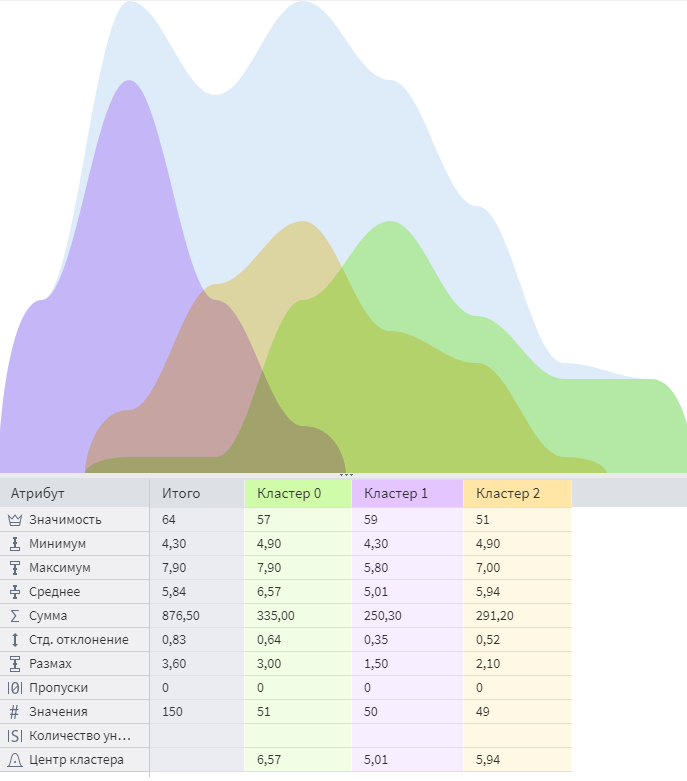
Алгоритм выделил 3 кластера, которые совпадают с количеством исходных классов и примерно равны, что говорит о хорошей работе алгоритма EM кластеризации.
2.2 Кластеризация k-means
Кластеризация k-means применяется в том случае, если известно количество кластеров.
Установлены следующие настройки для узла Кластеризация (k-means):
- для полей
sepal_length,sepal_width,petal_length,petal_width— назначение Используемое - в параметре Заданное число кластеров значение равное — 3
- остальные настройки по умолчанию
В случае изменения настроек переобучите модель.
Интерпретация результатов
В выходном наборе появляются две новые колонки, которые добавились к исходному набору:
- Номер кластера
- Расстояние до центра кластера
| 2 | 0.23 | 5.10 | 3.50 | 1.40 | 0.20 | Iris-setosa |
| ... | ... | ... | ... | ... | ... | ... |
| 0 | 0.95 | 7.0 | 3.20 | 4.70 | 1.40 | Iris-versicolor |
| ... | ... | ... | ... | ... | ... | ... |
| 0 | 1.06 | 5.90 | 3.0 | 5.10 | 1.80 | Iris-virginica |
Интерпретацию результатов Кластеризации (k-means) можно посмотреть в визуализаторе Профили кластеров:

В визуализаторе Профили кластеров возможно посмотреть статистические показатели, по которым можно сравнить кластеры между собой:
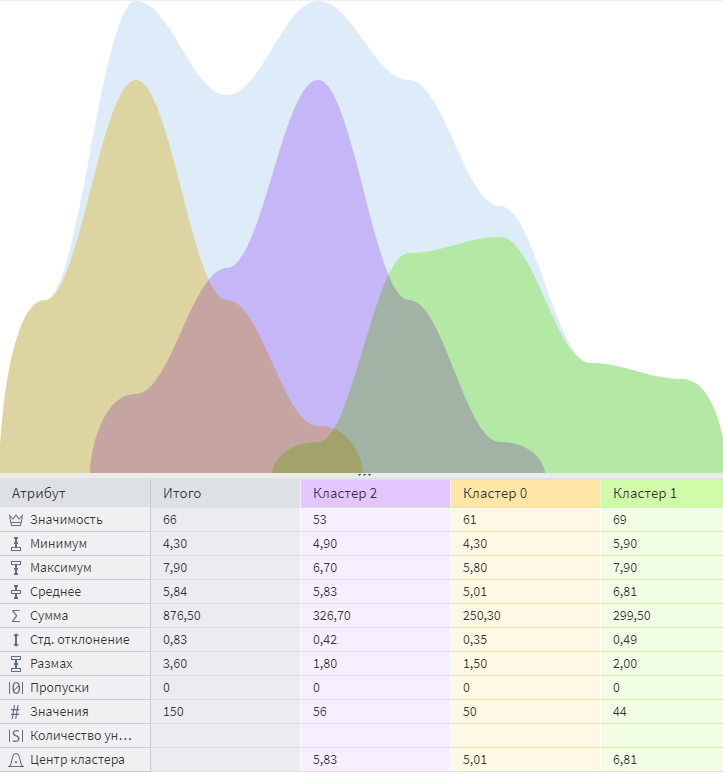
Алгоритм выделил 3 кластера, которые совпадают с количеством классов входного набора, однако в каждом кластере получилось сильно различающееся количество объектов. Таким образом, k-means кластеризация менее точна, чем EM.
2.3 Кластеризация g-means
Кластеризация g-means применяется в том случае, если изначально неизвестно количество кластеров. Обработчик автоматически определяет их.
Установлены следующие настройки для узла Кластеризация (g-means):
- для полей
sepal_length,sepal_width,petal_length,petal_width— назначение Используемое - флаг Автоопределение числа кластеров - установлен
- остальные настройки по умолчанию
В случае изменения настроек переобучите модель.
Интерпретация результатов
В выходном наборе появляются две новые колонки, которые добавились к исходному набору:
- Номер кластера
- Расстояние до центра кластера
| 0 | 0.23 | 5.10 | 3.50 | 1.40 | 0.20 | Iris-setosa |
| ... | ... | ... | ... | ... | ... | ... |
| 1 | 1.23 | 7.0 | 3.20 | 4.70 | 1.40 | Iris-versicolor |
| ... | ... | ... | ... | ... | ... | ... |
| 1 | 0.56 | 5.9 | 3.0 | 5.10 | 1.80 | Iris-virginica |
Интерпретацию результатов Кластеризации (g-means) можно посмотреть в визуализаторе Профили кластеров:

В визуализаторе Профили кластеров возможно посмотреть статистические показатели, по которым можно сравнить кластеры между собой:
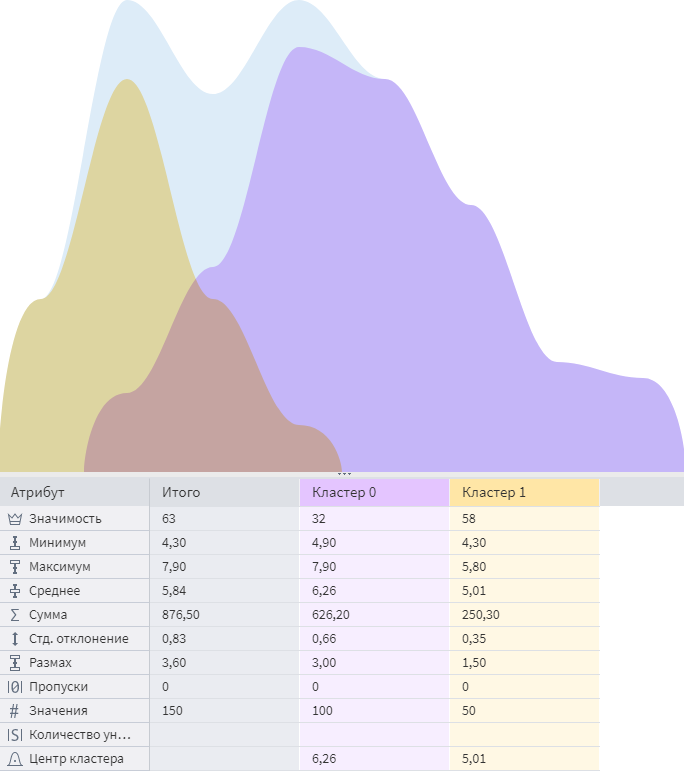
Алгоритм выделил 2 кластера, которые, во-первых, не совпадают с количеством классов исходного набора, а, во-вторых, получились неравномерными. Таким образом, g-means кластеризация оказалась наименее точной, и ее результаты можно оценить как неудовлетворительные.
Алгоритмы кластеризации на службе Data Mining
Скачайте и откройте файл в Loginom. При необходимости Loginom CE можно скачать бесплатно
Минимальные требования к системе:
- Операционная система: Windows 10 и выше
- CPU x64: 2 core 1
- Оперативная память: 4 GB
- Жесткий диск: 10 GB
1 Поддерживается работа на x64 процессорах Intel Core, AMD FX и более новых, содержащих инструкции SSE4.2, POPCNT.